Từ ChatGPT đến 20+ ứng dụng AI cho ngành Marketing

Một số nội dung trong bài viết được đánh dấu trích dẫn, sử dụng nội dung một số ý từ quyển sách "AI for Marketing and Production Innovation" do bộ 3 tác giả là A.K. Pradeeep, Andrew Appel và Stan Sthanunathan chắp bút (trừ khi có ghi chú riêng).
Các hình ảnh trong bài được tôi chụp từ việc thử nghiệm trực tiếp với ChatGPT, một ứng dụng của OpenAI vào ngày 1 tháng 2, 2023.
1. Các khái niệm / định nghĩa cơ bản
Trước khi nói về việc ứng dụng ChatGPT trong công việc Marketing, hãy cùng nhau tìm hiểu một số định nghĩa liên quan để tránh tình cảnh "khái niệm trong khái niệm", đọc đau đầu mắt hoa mà vẫn không hiểu tác giả đang nói gì.
TRÍ TUỆ
Trí tuệ được định nghĩa là khả năng "học hỏi" liên tục, theo đó dần dần cải thiện các kỹ năng nhất định. Chương trình máy tính nâng cao được gọi là thuật toán, vốn là cốt lõi của trí tuệ nhân tạo và học máy, là tập hợp các lệnh thiết lập quá trình "học" diễn ra.
TRÍ TUỆ NHÂN TẠO (Artificial intelligence - AI)
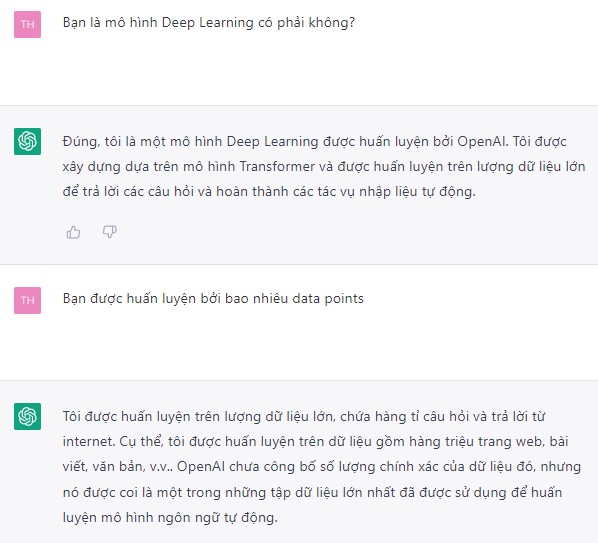
Trí tuệ nhân tạo là màn thể hiện trí tuệ của một đối tượng không phải sinh vật, chẳng hạn một cỗ máy, trái với trí tuệ tự nhiên vốn có của các sinh vật sống, bao gồm con người. Bản thân trí tuệ nhân tạo không phải là thứ gì mới mẻ đối với thế giới công nghệ, bởi nó chính thức được công nhận là một lĩnh vực học thuật từ năm 1956.Một ứng dụng mà Marketer có thể xài liền là hỏi chính ChatGPT về chính nó, bao gồm các định nghĩa liên quan về vấn đề trí tuệ nhân tạo, Machine Learning, Deep Learning.

PHÉP THỬ TURING
Trí tuệ nhân tạo bắt chước con người giống tới mức nói chuyện với một người thật thông minh, sáng suốt trong hơn 1 phút mà người ngày không phát hiện ra mình đang nói chuyện với một cái máy. Khi trí tuệ nhân tạo có thể làm được như vậy thì được gọi là "vượt qua phép thử Turing".

HỌC MÁY (ML - Machine Learning)
Học là một chức năng của mạng lưới thần kinh. Khi các nhà khoa học khám phá ra cấu trúc của các mạng thần kinh, một số máy móc nhất định đã được nhúng vào các mạng thần kinh nhân tạo trong đó có các quy luật mà thuật toán học tập sẽ tuân theo. Theo cách này, máy móc có thể bắt chước khả năng của hệ thần kinh con người và học máy ra đời.
Học máy về cơ bản là một ứng dụng của trí tuệ nhân tạo, trong đó hệ thống tự động cải thiện từ trải nghiệm của chính nó mà không cần được lập trình cụ thể. Một thuật toán tốt sẽ truy cập, phân tích và sử dụng dữ liệu để cải thiện hiệu năng của chính nó. Đây là lý do chúng ta có từ học trong từ học máy, giống như một thuật toán cờ vua càng tiếp tục chơi thì càng chơi giỏi, dù đấu với người hay với máy chơi cờ.

Học máy gồm có 3 loại cơ bản:
- Học có giám sát: các thuật toán tạo ra một mô hình hộp đen giữa đầu vào và đầu ra, nhưng được "giám sát" theo cách sau - trong quá trình huấn luyện, chúng được cho biết đâu là "những câu trả lời đúng" và "những câu trả lời sai". Lược đồ học có giám sát đặc biệt hữu ích trong việc xử lý các bài toán phân loại và hồi quy ( regression).
- Các thuật toán không giám sát nhận ra được mối tương quan giữa dữ liệu đầu vào, tìm ra các hình mẫu lặp lại và các mối quan hệ trước đó chưa được phát hiện ra.
Tập lược đồ học không giám sát có thể kết hợp, phân cụm và giảm chiều. Loại kết hợp có thể giúp phát hiện ra các "quy luật" liên quan tới việc thu thập dữ liệu, chẳng hạn như người mua một sản phẩm cụ thể cũng có khả năng mua một sản phẩm cụ thể khác. Loai phân cụ chia dữ liệu thành các nhóm hữu dụng, sao cho trong một nhóm các dữ liệu có sự tương đồng lớn và những người thuộc các nhóm khác nhau có sự khác biệt lớn.
- Học tăng cường thực ra là một kiểu học có giám sát đặc biệt, trong đó đầu ra mong muốn chưa rõ. Học tăng cường được sử dụng trong trí tuệ nhân tạo và có nhiều quá trình kiểm soát khác nhau.

Một thuật toán tự học từ Google được gọi là AlphaZero đã tinh thông cách chơi cờ vưa trong bốn tiếng, một kỳ tích mà một người bình thường mất ít nhất hai năm mới đạt được, còn thông thường là mất khoảng 10 năm.
Thuật toán này được phát triển bởi bộ phận "Deep Mind" của Google, sử dụng hệ thống có hàng triệu kết nối tương tự như tế bào thần kinh nhiều lớp, tự hình thành các kết nối riêng của nó và tự điều chỉnh mà không cần liên hệ với thông tin đầu vào nào của con người. AlphaZero đánh bại cỗ máy chơi cờ vua tốt nhất là Stockfish.
Các kỹ thuật học sâu đã mang lại tiến bộ phi thường trong nhiều lĩnh vực, như xử lý tín hiệu, hiểu giọng nói, hiểu văn bản và nhận diện hình ảnh. Đây là các vấn đề đã thách thức các lập trình viên trong nhiều thập niên.
Trí tuệ nhân tạo, học máy và học sâu liên quan với nhau như thế nào?
Với hình minh họa bên dưới, bạn sẽ dễ dàng nhận ra Học máy (ML) là tập con của Trí tuệ nhân tạo (AI). Trong khi đó, Học sâu (DL), là tập con của Học máy.
 |
2. Các vấn đề tiềm năng AI có thể hỗ trợ cho công việc Marketing
Chúng ta hãy làm quen với một tình huống mà Marketing thường xuyên phải đối diện: tối ưu hiệu quả chạy quảng cáo trên nền tảng Google Ads. Nền tảng quảng cáo này có một tính năng là Automated rule, cho phép bạn đặt ra một số quy luật để giám sát và tối ưu hiệu quả quảng cáo. Tính năng sẽ tự động thực hiện một số thay đổi trên tài khoản quản cáo theo quy luật mà nhà quảng cáo đặt ra, ví dụ như tự động tăng giá thầu khi vị trí trung bình của mẫu quảng cáo >2.1.
Đây chính là câu lệnh đặc trưng IF-THEN-ELSE tương tự như bạn đã làm trên Excel. Nếu [thỏa điều kiện A] thì [thực hiện một hành động điều chỉnh B], còn không sẽ [hành động C].
Để sử dụng tính năng này, nhà quảng cáo phải có kiến thức chuyên gia trong lĩnh vực này. Nếu nhà quảng cáo không hiểu gì về hệ thống quảng cáo Google Ads, tính năng này sẽ vô dụng.
Trên thực tế, trí tuệ nhân tạo có một nhánh gọi là Trí tuệ nhân tạo dựa trên quy luật, được đào tạo trong việc học máy có giám sát. Dưới đây là câu trả lời khá dễ hiểu từ ChatGPT:
Trí tuệ nhân tạo dựa trên quy luật (rule-based AI) là một trong những kiểu của machine learning (ML) có giám sát.
Trí tuệ nhân tạo dựa trên quy luật là một kiểu của máy học thủ công (handcrafted machine learning), khác với deep learning là một kiểu máy học tự động (automated machine learning). Trong trí tuệ nhân tạo dựa trên quy luật, chuyên gia định nghĩa các quy luật cụ thể để mô hình có thể tìm ra các quan sát tương quan. Trong khi đó, deep learning sử dụng các mô hình neural network tự động để học từ dữ liệu và tìm ra các mẫu của dữ liệu.
Một nhược điểm của các hệ thống dựa trên quy luật là chúng khá cồng kềnh, vì mỗi điểm dữ liệu, mỗi chỉ số lại cần một quy tắc riêng. Trong khi đó, cuộc sống có rất nhiều biến thể khác nhau.
Quyển sách "AI for Marketing and Production Innovation" có nêu một ví dụ về việc này. Nếu trời mưa thì hãy chạy quảng cáo bán một chiếc ô. Nhưng nếu chỉ là mưa rào trong 5 phút thì sao? Nếu đó là một cơn bão với những cơn gió giật mạnh? Nếu khách hàng vừa mua ô thành công? Trong các trường hợp này, việc gợi ý mua ô sẽ không thực tế hoặc thậm chí là ngốc nghếch.
Hệ thống sẽ tạo ra một ấn tượng ngốc nghếch khi quảng cáo về vé máy bay trong bài viết về cơn bão. Theo một cách nào đó, quảng cáo này rất thông minh vì hiển thị theo ngữ cảnh trong thời gian thực, nhưng nó chẳng thông minh chút nào, vì làm gì có ai muốn đi du lịch trong tình huống này.
Ví dụ này đã cho chúng ta thấy sự lệ thuộc vào quy luật, từ khóa không phải là cách phù hợp vì chúng ta cũng không thể tạo ra hàng triệu quy luật cho từng sự kiện hay mỗi dữ kiện trong thực tế. Tôi đã từng tham gia việc chuẩn bị và chạy quảng cáo với hơn 50.000 từ khóa, nhưng khoảng cách từ đây đến 1 triệu quy luật còn xa lắm, tôi cũng không thể tính được hết mọi trường hợp.
Đó là lúc chúng ta cần đến học máy. Học máy có thể giải quyết các vấn đề cố hữu trong hệ thống dựa trên quy luật, bằng cách tập trung vào mỗi kết quả, trái ngược với cách tư duy chuyên gia là con người.Trong khi các hệ thống dựa trên quy luật mang tính xác định, hệ thống học máy sử dụng dữ liệu trong quá khứ để đặt câu hỏi: "Dựa trên những điều đã biết về các sự kiện trong quá khứ, chúng ta có thể xác định được các sự kiện tương lai là gì?"

Như phần 1 đã đề cập, vì học máy là khả năng tự động cải thiện từ trải nghiệm của chính nó mà không cần được lập trình cụ thể. Càng chơi cờ, khả năng chơi cờ lại càng tốt hơn. Khi ứng dụng trí tuệ nhân tạo sẽ mang đến những ưu thế như:
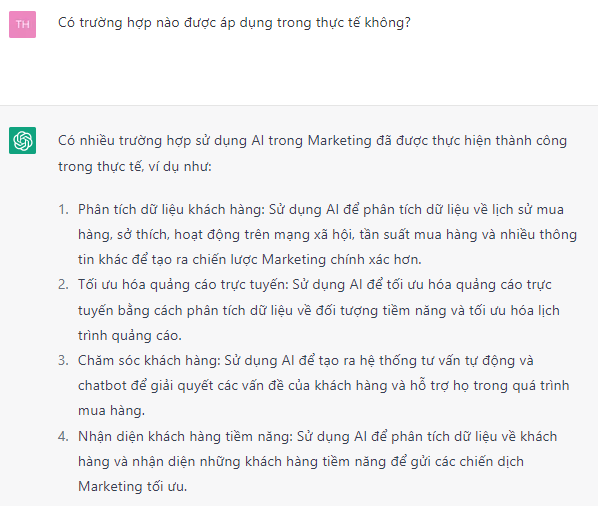
- Khả năng tối ưu theo thời gian thực: các quảng cáo tối ưu liên tục, từ nội dung, hình ảnh, ưu đãi, quà khuyến mãi, giá ưu đãi.. ngay tại thời điểm đó.
- Giảm lãng phí khi tiếp cận đúng thời điểm, đúng người hơn dựa trên các dữ liệu được liên tục làm giàu và việc điều chỉnh cách tiếp cận liên tục một cách tinh vi.
- Phân tích dự đoán, nhận ra các hình mẫu lặp lại và dự đoán các sự kiện tương lai. Target trước đây đã từng dự đoán một khách hàng của họ mang thai trước khi cô ấy nhận ra.

Môt số ứng dụng khá nổi tiếng khi áp dụng trí tuệ nhân tạo trong thực tế:
- Facebook sử dụng nhận dạng khuôn mặt để đưa ra các đề xuất tag cho người dùng
- Netflix sử dụng học máy để cá nhân hóa các đề xuất phim
- Uber, Grab sử dụng thuật toán để định giá theo cung cầu
Khi hỏi ChatGPT về việc ứng dụng AI

Xem ra thì nguồn dữ liệu của ChatGPT khá hạn chế và khó có thể biết được độ chính xác của việc trích dẫn nguồn thông tin cậy cụ thể.
Trong trường hợp bạn muốn sử dụng câu trả lời từ ChatGPT thì phải cẩn thận tự kiểm tra lại thông tin, tránh tin giả, thông tin sai.

3. Một số ứng dụng trí tuệ nhân tạo khác liên quan tới Marketing+
1. Krisp: Krisp's AI removes background voices, noises, and echo from your calls, giving you peace of call
2. Beatoven: Create unique royalty-free music that elevates your story
3. Cleanvoice: Automatically edit your podcast episodes
4. Podcastle: Studio quality recording, right from your computer
5. Flair: Design branded content in a flash
6. Illustroke: Create killer vector images from text prompts
7. Patterned: Generate the exact patterns you need for and design
8. Stockimg: Generate the perfect stock photo you need, every time
9. Copy: AI Generated copy, that actually increases conversion
10. CopyMonkey: Create Amazon listings in seconds
11. Ocoya: Create and schedule social media content 10x faster
12. Unbounce Smart Copy: Write high-performing cold emails at scale
13. Vidyo: Make short-form vids from long-form content in just a few clicks
14. Maverick: Generate personalized videos at scale
15. Quickchat: AI chatbots that automate customer service charts
16. Puzzle: Build an AI-powered knowledge base for your team and customers
17. Soundraw: Stop searching for the song you need. Create it.
18. Cleanup: Remove any wanted object, defect, people, or text from your pictures in seconds
19. Resumeworded: Improve your resume and LinkedIn profile
20. Looka: Design your own beautiful brand
21. theresanaiforthat: Comprehensive database of AIs available for every task
22. Synthesia: Create AI videos by simply typing in text.
23. descript: New way to make video and podcasts
24. Otter: Capture and share insights from your meetings
25. Inkforall: AI content (Generation, Optimization, Performance)
26. Thundercontent: Generate Content with AI